本文介绍的算法根据 v1.8.0 版本游戏 apk 逆向解析获取,不排除人为解析失误以及后续版本算法被修改的情形。
大约在两个月以前,我发布了一篇介绍学玛仕自动打牌算法的文章 。
文章发布一段时间后,收到了来自 kanon511 的回复,称游戏中的实际自动打牌算法和文章介绍的算法有所出入,存在几个疑问点,希望能得到解答。「反正这些文章也没人看懒得管了」的想法,虽然感觉到有不对劲儿的地方,但还是懒得继续研究,把问题放置下去了。
但以此回复为契机,我决定把 Contest 的打牌机制彻底弄清楚,于是肝了周末两天时间,把整个逻辑理顺了。
结论是,游戏中的四种 ExamPlayType,
1 2 3 4 5 6 7 enum ExamPlayType { Unknown = 0 ; AutoPlay = 1 ; ManualPlayLesson = 2 ; ManualPlayLessonHard = 3 ; ManualPlayAudition = 4 ; }
中,上一篇文章中介绍的算法是适用于 Manual 的三种场次的,但 Contest 和 GvG 所属的 AutoPlay 存在额外的逻辑。
本文主要针对 AutoPlay 的算法进行展开介绍。
Outline 首先对游戏中自动打牌 AI 的行为做一个概述。
我们都知道,如果以准确率至上为原则,以穷举法模拟出牌永远是最佳的选择。因为只要把每一回合的所有出牌选项都模拟一遍,那么只要取出最后得分最高的一次模拟,便可以绘制出一条整场游戏的最佳出牌路线。3 10 3^{10} 3 10
于是 QA 的开发者们想出来一种方式,以阶段性的穷举 (a.k.a. 贪心) 来实现 AI 的运算逻辑。我将其称作阶段性深度优先遍历模拟算法 。
阶段性是指以固定的回合数为一个 calculateTurn,对 calculateTurn 内的所有出牌可能性进行穷举模拟。
实现方式可在 Campus.InGame.Contest.ExamDepthFirstSearchSimulator 中找到。
calculateTurn calculateTurn 是 AI 模拟一轮出牌路线的间隔回合数。
calculateTurn 的值根据 planType 而变,目前游戏中定义的如下:
1 2 3 4 5 6 7 enum ProducePlanType { ProducePlanType_Unknown = 0 ; ProducePlanType_Common = 1 ; ProducePlanType_Plan1 = 2 ; ProducePlanType_Plan2 = 3 ; ProducePlanType_Plan3 = 4 ; }
从 Campus.InGame.ExamExtensions.GetContestCalculateTurn 中可找到获取 calculateTurn 的逻辑。
对每一轮 calculateTurn 内的出牌选项穷举后,对每个结果计算 evaluation,取 evaluation 最大的一条出牌路线作为在该 calculateTurn 内最终出牌结果。
例如,在一轮总共 10 个回合的游戏局中,如果 calculateTurn = 2,则将游戏拆分为剩余回合数为 [10, 9], [8, 7], [6, 5], [4, 3], [2, 1] 的 5 个阶段,分别穷举模拟每个阶段的所有出牌选项,取其中 evaluation 最大的路线最为该阶段的出牌结果。
remainingTerm remainingTerm 是在获取主数据库 ProduceExamAutoEvaluation 中的 evaluation 值的时候对应的剩余模拟回合数 。
请注意 remainingTerm 和 remainingTurn 的书写区别。remainingTerm 并不是指剩余回合数,而是剩余模拟回合数 。remainingTerm 通过以下公式计算:
1 remainingTerm = remainingTurns / calculateTurn + 1
即,如果当前实际剩余回合数为 8,则对应的主数据库中的 remainingTerm 应为 8 / 2 + 1 = 5。
evaluation 计算时机 evaluation 的计算时机分为最后一回合和除最后一回合两种情况。
例如,要计算剩余回合数为 [8, 7] 这个阶段的 evaluation,计算的时机是在剩余 6 回合的开始时。evaluation,由于是最后一回合所以计算时机是在最终回合结束时。
evaluation 计算方法 由于版本更新,在 v1.6.0 版本中,计算 evaluation 所需的参数从 v1.4.0 的 19 个增加到了 29 个,所以这里对其重新进行介绍,也方便没有读过前一篇文章的读者理解。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 r1_JudgeParameter r2_Block r3_Stamina r4_LessonBuff r5_Review r6_Aggressive r7_min_ParameterBuffTurn r8_min_StaminaConsumptionDownTurn r9_min_StaminaConsumptionAddTurn r10_min_BlockAddDown r11_LessonDebuff r12_min_ParameterDebuff r13_BlockAddDownFix r14_min_SlumpTurn r15_StaminaConsumptionDownFix r16_PlayableValueAddCount r17_min_ParameterBuffMultiplePerTurn r18_ParameterBuffTurnOver r19_ExtraTurn r20_Concentration r21_Preservation r22_FullPower r23_FullPowerPointGetSumCount r24_StanceConcentrationChangeCount r25_StancePreservationChangeCount r26_StanceFullPowerChangeCount r27_holdCount r28 主数据库 ProduceExamAutoGrowEffectEvaluation 中的对应值 r29 特殊参数
evaluation 的值由上述 29 个参数的和加上 0.0000999999975 后舍弃小数点取整而得:
E e v a = ⌊ ∑ 1 ≤ n ≤ 29 r n + 0.0000999999975 ⌋ \boxed{\begin{equation}
\begin{split}
E_\mathrm{eva}
&=\lfloor \sum_{\mathclap{1\le n\le 29}}r_n + 0.0000999999975 \rfloor
\end{split}
\end{equation}
} E eva = ⌊ 1 ≤ n ≤ 29 ∑ r n + 0.0000999999975 ⌋ 这里就不举例说明了(懒),想看如何求 r n r_n r n 上一篇文章 里的例子。
为了方便我们将 r1 ~ r27 称为一般参数,r28 称为卡片增长评估参数,r29 称为特殊参数。
r1 ~ r27 一般参数 r1 至 r27 由主数据库 ProduceExamAutoEvaluation 中对应的 evaluation 值与当前游戏中对应的效果层数的积而得:
r n = v n × e e v a \boxed{r_n = v_n \times e_\mathrm{eva}} r n = v n × e eva 其中,e e v a e_\mathrm{eva} e eva ProduceExamAutoEvaluation 中对应的 evaluation 值,v n v_n v n
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 v1_JudgeParameter: 当前已获得的总分 v2_Block: 当前元气值 v3_Stamina: 当前体力值 v4_LessonBuff: 当前集中值 v5_Review: 当前好印象值 v6_Aggressive: 当前やる気值 v7_min_ParameterBuffTurn: min(当前好调回合数, 剩余回合数) v8_min_StaminaConsumptionDownTurn: min(当前体力消费减少回合数, 剩余回合数) v9_min_StaminaConsumptionAddTurn: min(当前体力消费增加回合数, 剩余回合数) v10_min_BlockAddDown: min(当前不安回合数, 剩余回合数) v11_LessonDebuff: 当前緊張值 v12_min_ParameterDebuff: min(当前不调回合数, 剩余回合数) v13_BlockAddDownFix: 当前弱气值 v14_min_SlumpTurn: 当前スランプ回合数 v15_StaminaConsumptionDownFix: 当前消費体力削減数 v16_PlayableValueAddCount: 当前可使用卡片数(每回合自然分配的使用次数也算在其内) v17_min_ParameterBuffMultiplePerTurn: min(当前绝好调回合数,剩余回合数) v18_ParameterBuffTurnOver: 当前好调回合数 v19_ExtraTurn: 额外追加回合数 v20_Concentration: 当前強気层数 v21_Preservation: 当前温存层数 v22_FullPower: 当前全力层数 v23_FullPowerPointGetSumCount: (暂不知含义,待 anomaly 实装后验证) v24_StanceConcentrationChangeCount: (暂不知含义,待 anomaly 实装后验证) v25_StancePreservationChangeCount: (暂不知含义,待 anomaly 实装后验证) v26_StanceFullPowerChangeCount: (暂不知含义,待 anomaly 实装后验证) v27_holdCount: 当前手牌数
r1 在 battle 中的特殊情况 当且仅当计算 v1 时,会有一个补充条件分支。
r 1 = r o u n d ( v 1 × 3000 P d a + P v o + P v i + 0.0000999999975 , 6 ) \boxed{r_1 = \mathrm{round(}\frac {v_1 \times 3000} {P_\mathrm{da} + P_\mathrm{vo} + P_\mathrm{vi}} + 0.0000999999975 \mathrm{,\ 6)}} r 1 = round ( P da + P vo + P vi v 1 × 3000 + 0.0000999999975 , 6 ) 其中 P d a , P v o , P v i P_\mathrm{da}, P_\mathrm{vo}, P_\mathrm{vi} P da , P vo , P vi
注意最后要将得到的结果四舍五入取 6 位小数。
r28 卡片增长评估参数 这是 v1.6.0 中新增的评估参数,与 “卡片成长” 效果有关。ProduceExamAutoGrowEffectEvaluation 中对应的值求积后累加起来而得。
r 28 = ∑ n ( N n × e e v a n ) \boxed{r_{28} = \sum_n (N_\mathrm{n} \times e_\mathrm{eva_n})} r 28 = n ∑ ( N n × e ev a n ) 其中,e e v a n e_\mathrm{eva_n} e ev a n ProduceExamAutoGrowEffectEvaluation 中对应的第 n \mathrm{n} n evaluation 值,N n N_\mathrm{n} N n 不含已除外卡片 卡组中受到第 n \mathrm{n} n n n n ProduceCardGrowEffectType 对应的枚举序号。
目前存在的 ProduceCardGrowEffectType 如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 enum ProduceCardGrowEffectType { ProduceCardGrowEffectType_Unknown = 0 ; ProduceCardGrowEffectType_LessonAdd = 1 ; ProduceCardGrowEffectType_LessonReduce = 2 ; ProduceCardGrowEffectType_LessonCountAdd = 3 ; ProduceCardGrowEffectType_LessonCountReduce = 4 ; ProduceCardGrowEffectType_BlockAdd = 5 ; ProduceCardGrowEffectType_BlockReduce = 6 ; ProduceCardGrowEffectType_FullPowerPointAdd = 7 ; ProduceCardGrowEffectType_FullPowerPointReduce = 8 ; ProduceCardGrowEffectType_CostBuffReduce = 10 ; ProduceCardGrowEffectType_CostBuffAdd = 11 ; ProduceCardGrowEffectType_CostReduce = 12 ; ProduceCardGrowEffectType_CostAdd = 13 ; ProduceCardGrowEffectType_CostPenetrateReduce = 14 ; ProduceCardGrowEffectType_CostPenetrateAdd = 15 ; ProduceCardGrowEffectType_ParameterBuffTurnAdd = 16 ; ProduceCardGrowEffectType_ParameterBuffTurnReduce = 17 ; ProduceCardGrowEffectType_LessonBuffAdd = 18 ; ProduceCardGrowEffectType_LessonBuffReduce = 19 ; ProduceCardGrowEffectType_ReviewAdd = 20 ; ProduceCardGrowEffectType_ReviewReduce = 21 ; ProduceCardGrowEffectType_AggressiveAdd = 22 ; ProduceCardGrowEffectType_AggressiveReduce = 23 ; ProduceCardGrowEffectType_CardDrawAdd = 24 ; ProduceCardGrowEffectType_CardDrawReduce = 25 ; ProduceCardGrowEffectType_ParameterBuffMultiplePerTurnAdd = 26 ; ProduceCardGrowEffectType_ParameterBuffMultiplePerTurnReduce = 27 ; ProduceCardGrowEffectType_StaminaConsumptionDownTurnAdd = 28 ; ProduceCardGrowEffectType_StaminaConsumptionDownTurnReduce = 29 ; ProduceCardGrowEffectType_StaminaConsumptionAddTurnAdd = 30 ; ProduceCardGrowEffectType_StaminaConsumptionAddTurnReduce = 31 ; ProduceCardGrowEffectType_EffectAdd = 32 ; ProduceCardGrowEffectType_EffectDelete = 33 ; ProduceCardGrowEffectType_EffectChange = 34 ; ProduceCardGrowEffectType_CardStatusEnchantChange = 35 ; ProduceCardGrowEffectType_PlayTriggerChange = 36 ; ProduceCardGrowEffectType_PlayEffectTriggerChange = 37 ; ProduceCardGrowEffectType_PlayMovePositionTypeChange = 38 ; ProduceCardGrowEffectType_InitialAdd = 39 ; ProduceCardGrowEffectType_CostLessonBuffReduce = 40 ; ProduceCardGrowEffectType_CostLessonBuffAdd = 41 ; ProduceCardGrowEffectType_CostReviewReduce = 42 ; ProduceCardGrowEffectType_CostReviewAdd = 43 ; ProduceCardGrowEffectType_CostAggressiveReduce = 44 ; ProduceCardGrowEffectType_CostAggressiveAdd = 45 ; ProduceCardGrowEffectType_CostParameterBuffReduce = 46 ; ProduceCardGrowEffectType_CostParameterBuffAdd = 47 ; ProduceCardGrowEffectType_CostFullPowerPointReduce = 48 ; ProduceCardGrowEffectType_CostFullPowerPointAdd = 49 ; ProduceCardGrowEffectType_LessonDependBlockAdd = 50 ; ProduceCardGrowEffectType_LessonDependExamCardPlayAggressiveAdd = 51 ; ProduceCardGrowEffectType_LessonDependExamReviewAdd = 52 ; }
计算实例 以以下情况为例:
当前整个卡组中排除除外卡以外共有 2 枚卡牌被附加了成长效果,这些效果分别是「スコア値増加」「スコア上昇回数増加」「コスト値増加」。ManualPlayAudition,角色类型是全力,剩余 4 回合,在数据库中找到对应的项目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 - type: ExamPlayType_ManualPlayAudition examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 4 growEffectType: ProduceCardGrowEffectType_LessonAdd evaluation: 92 examStatusEnchantCoefficientPermil: 1326 - type: ExamPlayType_ManualPlayAudition examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 4 growEffectType: ProduceCardGrowEffectType_LessonCountAdd evaluation: 2114 examStatusEnchantCoefficientPermil: 1328 - type: ExamPlayType_ManualPlayAudition examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 4 growEffectType: ProduceCardGrowEffectType_CostReduce evaluation: 293 examStatusEnchantCoefficientPermil: 3997
注意上述的「コスト値増加」对应的 growEffectType 实际上应该是 ProduceCardGrowEffectType_CostAdd,但主数据库为了节省空间 ProduceExamAutoGrowEffectEvaluation 中只包含 positive 的成长效果,所以这里应选择与其成对的 ProduceCardGrowEffectType_CostReduce,并在计算时乘以 -1(减去)。
这 2 枚卡片中有 2 张卡带有 ProduceCardGrowEffectType_LessonAdd 成长效果,有 1 张卡带有 ProduceCardGrowEffectType_LessonCountAdd 成长效果,有 1 张卡带有 ProduceCardGrowEffectType_CostAdd 效果。
1 2 3 4 r28 = 92 * 2 // スコア値増加 + 2114 * 1 // スコア上昇回数増加 + 293 * 1 * (-1) // コスト値増加 = 2005
注意这里的成长效果评价值只与受影响的卡片数量有关,与效果的层数无关。例如一张卡被附加「スコア上昇回数+1」,另一张卡被附加「スコア上昇回数+3」,在同一场游戏中这两张卡的成长评价值是相同的。
r29 特殊参数 特殊参数用于计算非直接效果的持续效果的 evaluation,比如「至高のエンタメ」「天真爛漫」「頂点へ」这种不便于直接评估的卡片效果。
顺带一提,在上一篇文章中对特殊参数的计算方式的描述有误,请以本文为准。
r29 由两个 multiplier 变量计算而得:
r 29 = ∑ n ⌊ m 1 n × m 2 n + 0.0001 ⌋ \boxed{\begin{equation}
\begin{split} r_{29}
&=\sum_n \lfloor m_{1n} \times m_{2n} + 0.0001 \rfloor
\end{split}
\end{equation}
} r 29 = n ∑ ⌊ m 1 n × m 2 n + 0.0001 ⌋ 其中,m 1 n m_{1n} m 1 n m 2 n m_{2n} m 2 n n n n
注意在累加之前要舍弃每个值的小数点后的值。
multiplier1 multiplier1 由如下计算方式而来:
m 1 = P c o e f f 1000 × T \boxed{m_1 = \frac {P_\mathrm{coeff}} {1000} \times T} m 1 = 1000 P coeff × T 其中,P c o e f f P_{\mathrm{coeff}} P coeff ProduceExamAutoTriggerEvaluation 中 coefficientPermil 的千分数,T T T
如果主数据库中不存在对应的 coefficientPermil,则默认赋值 coefficientPermil = 1。
multiplier2 multiplier2 由如下计算方式而来:
m 2 = ∑ 1 ≤ n ≤ 28 ( r n ′ × P e n c h a n t n 1000 ) + ∑ 1 ≤ m ≤ 52 ( g m ′ × v m × N m × P e n c h a n t m 1000 ) \boxed{\begin{equation}
\begin{split} m_2
&=\sum_{\mathclap{1\le n\le 28}}(r'_\mathrm{n} \times \frac {P_\mathrm{enchant_n}} {1000})
+\sum_{\mathclap{1\le m\le 52}}(g'_\mathrm{m} \times v_\mathrm{m} \times N_\mathrm{m} \times \frac {P_\mathrm{enchant_m}} {1000})
\end{split}
\end{equation}
} m 2 = 1 ≤ n ≤ 28 ∑ ( r n ′ × 1000 P enchan t n ) + 1 ≤ m ≤ 52 ∑ ( g m ′ × v m × N m × 1000 P enchan t m ) 这里有两个累加式,左边是通常效果的计算式,右边是成长效果的计算式。因为左右两式分别计算的是不同的效果,所以在单次计算中必有一个为 0,我们将其分开来看。
对于左边的通常效果计算式,其中,r n ′ r'_\mathrm{n} r n ′ 在当前回合发动 的实际效果由前述一般参数计算而得的 evaluation,P e n c h a n t n P_\mathrm{enchant_n} P enchan t n ProduceExamAutoEvaluation 中对应的 examStatusEnchantCoefficientPermil 的千分数。
对于右边的成长效果计算式,其中,g m ′ g'_\mathrm{m} g m ′ ProduceExamAutoGrowEffectEvaluation 中对应的 evaluation 值,v m v_\mathrm{m} v m N m N_\mathrm{m} N m (包括已除外的卡片在内) ,P e n c h a n t m P_\mathrm{enchant_m} P enchan t m ProduceExamAutoGrowEffectEvaluation 中对应的 examStatusEnchantCoefficientPermil 的千分数。
计算实例 以下图中的情况为例:
如果打出手牌中的「頂点へ」,那么首先分析该局游戏类型属于 ManualPlayAudition,角色类型是全力,剩余 4 回合,在数据库中找到对应的项目:
1 2 3 4 5 6 - type: ExamPlayType_ManualPlayAudition examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 4 growEffectType: ProduceCardGrowEffectType_LessonAdd evaluation: 92 examStatusEnchantCoefficientPermil: 1326
「頂点へ」的发动条件「ターン開始時任意の指針」在 ProduceExamAutoTriggerEvaluation 中对应的系数是:
1 2 3 - type: ExamPlayType_ManualPlayAudition examStatusEnchantProduceExamTriggerId: e_trigger-exam_start_turn-not-no_stance coefficientPermil: 900
「頂点へ」的效果会影响卡组中包括除外卡在内的共 6 张卡,效果值为得分 +4,根据上述公式:
1 2 3 4 5 m1 = 900 / 1000 * 4 m2 = 92 * 4 * 6 * 1326 / 1000 r29 = int(m1 * m2 + 0.0001) = 10540
保留卡片选择机制 当发动带有将卡片移送至保留的效果时,AI 会对所有可移动的卡片计算 evaluation,并选出值最大的一张卡进行移动。
E s e l = ⌊ ∑ 1 ≤ n ≤ 3 r n ⌋ \boxed{\begin{equation}
\begin{split}
E_\mathrm{sel}
&=\lfloor \sum_{\mathclap{1\le n\le 3}}r_n \rfloor
\end{split}
\end{equation}
} E sel = ⌊ 1 ≤ n ≤ 3 ∑ r n ⌋ r n r_n r n 所对应的评价类型如下:
1 2 3 4 5 6 enum ProduceExamAutoCardSelectEvaluationType { ProduceExamAutoCardSelectEvaluationType_Unknown = 0 ; ProduceExamAutoCardSelectEvaluationType_LessonCoefficient = 1 ; ProduceExamAutoCardSelectEvaluationType_FullPowerPointCoefficient = 2 ; ProduceExamAutoCardSelectEvaluationType_FullPowerPointValue2Coefficient = 3 ; }
这几个参数代表的效果如下:
1 2 3 r1_Lesson: 卡片的得分值 r2_FullPowerPoint: 卡片能获得的全力值 r3_FullPowerPointValue2Lesson: 卡片具有的全力值转得分值效果的得分值(即类似:「このレッスン中に増加した全力値の120%分、パラメータ上昇」这种效果)
各参数的计算方法类似:
r n = V n × E e v a n × P t g r n 1000 \boxed{\begin{equation}
\begin{split}
r_\mathrm{n}
&=V_\mathrm{n} \times E_\mathrm{eva_n} \times \frac {P_\mathrm{tgr_n}} {1000}
\end{split}
\end{equation}
} r n = V n × E ev a n × 1000 P tg r n 其中,V n V_\mathrm{n} V n E e v a n E_\mathrm{eva_n} E ev a n ProduceExamAutoCardSelectEvaluation 中对应的 evaluation,P t g r n P_\mathrm{tgr_n} P tg r n ProduceExamAutoTriggerEvaluation 中对应的 coefficientPermil。
计算实例 以以下情况为例:
该局游戏类型属于 AutoPlay,角色类型是全力,剩余 7 回合,在数据库中找到对应的项目:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 - type: ExamPlayType_AutoPlay examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 7 evaluationType: ProduceExamAutoCardSelectEvaluationType_LessonCoefficient evaluation: 424 - type: ExamPlayType_AutoPlay examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 7 evaluationType: ProduceExamAutoCardSelectEvaluationType_FullPowerPointCoefficient evaluation: 1501 - type: ExamPlayType_AutoPlay examEffectType: ProduceExamEffectType_ExamFullPower remainingTerm: 7 evaluationType: ProduceExamAutoCardSelectEvaluationType_FullPowerPointValue2Coefficient evaluation: 508
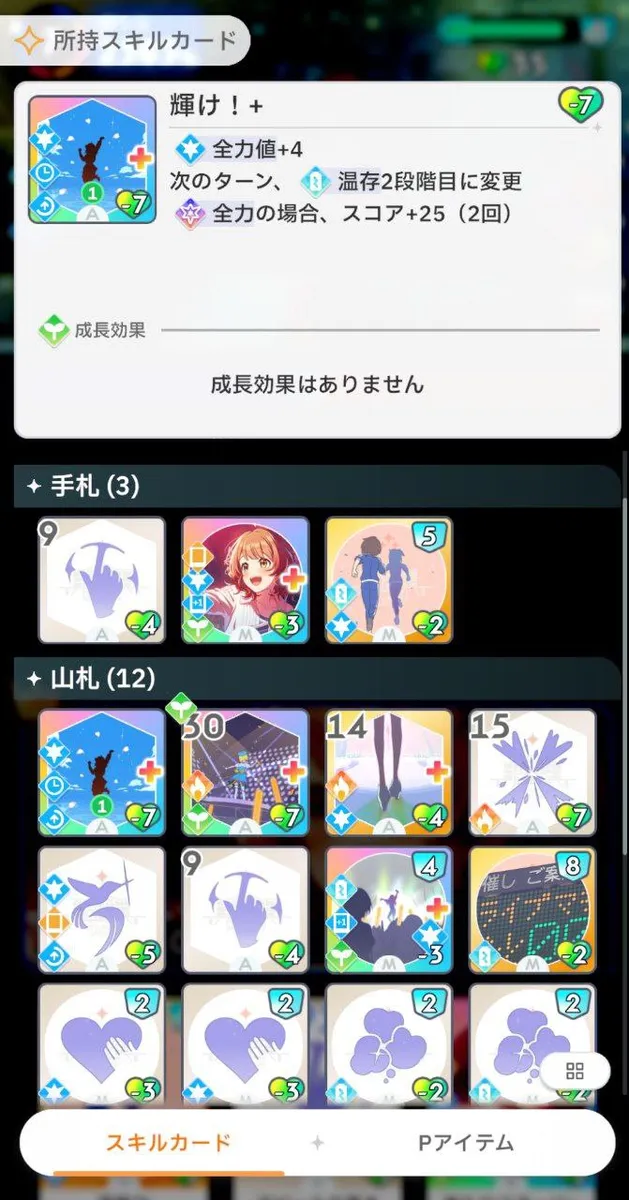
发动「新たなステージ+」后,AI 会评估山札和捨札中所有卡片,并选择 evaluation 最高的一张放入保留。这里为了节省时间我们只计算最终 AI 所选择的「輝け!+」的 evaluation 值。
「輝け!+」带有 2 种需要计算的效果,分别是 FullPowerPointCoefficient 和 LessonCoefficient,效果值是 4 和 25 * 2,并且 LessonCoefficient 具有触发条件 e_trigger-none-full_power_up (全力时),在主数据库中对应的项目是:
1 2 3 - type: ExamPlayType_AutoPlay examStatusEnchantProduceExamTriggerId: e_trigger-none-full_power_up coefficientPermil: 2000
根据公式求出该卡的 evaluation:
1 2 3 4 5 6 7 r1 = 25 * 2 * 424 * 2000 / 1000 = 42400 r2 = 4 * 1501 = 6004 r3 = 0 eva = r1 + r2 + r3 = 48404
注意这里的得分值不受 buff 和三属性得分加成的影响,必须是面板值,但会受到成长效果影响。
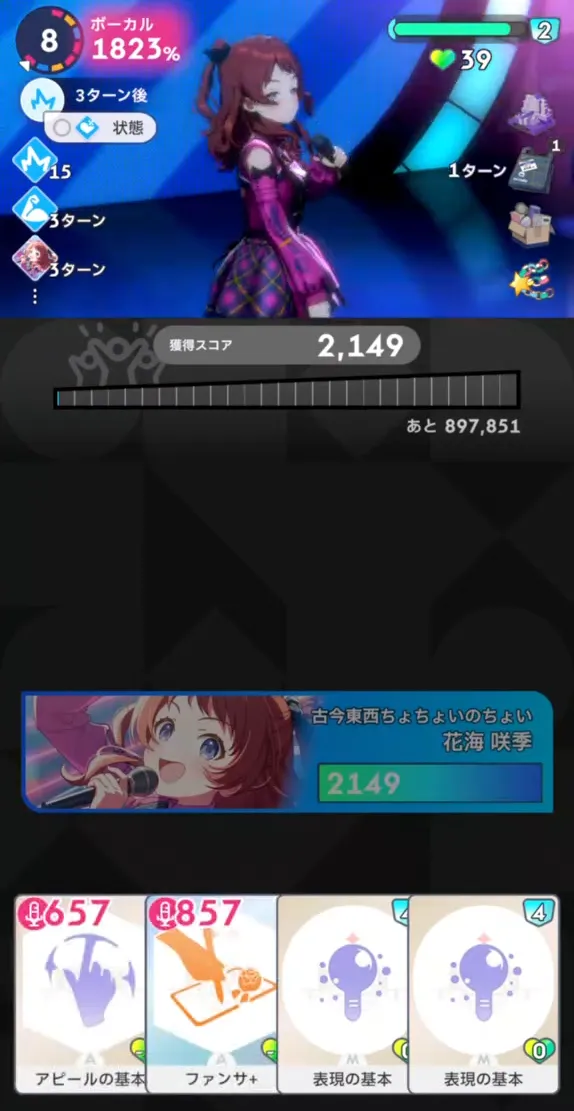
综合实例 这里以本次 GvG 中 B 号场为例来说明。
首先来看几张截图。
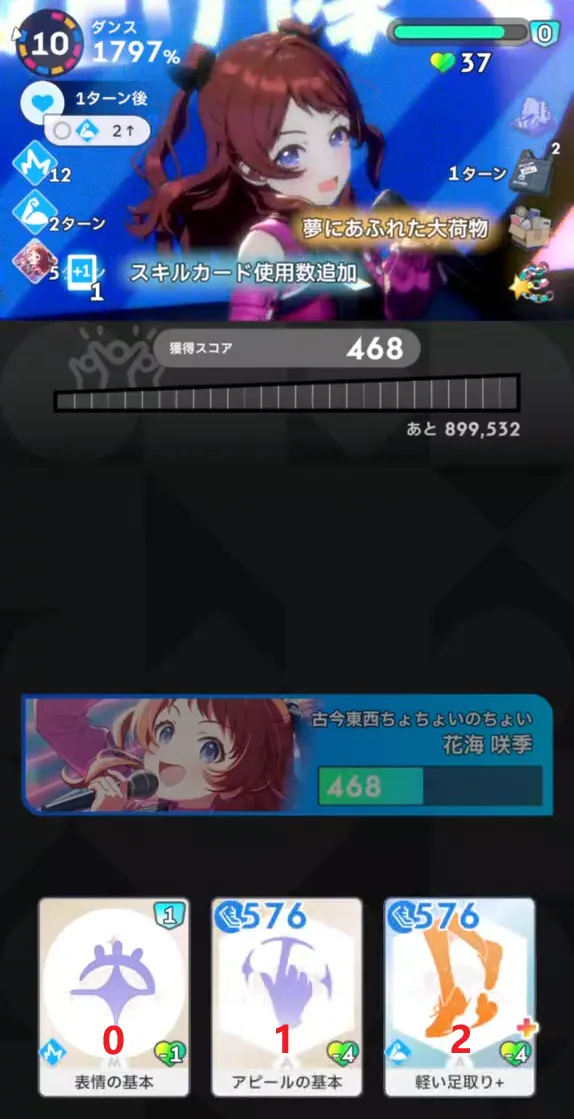
↑ 剩余 10 回合开始时
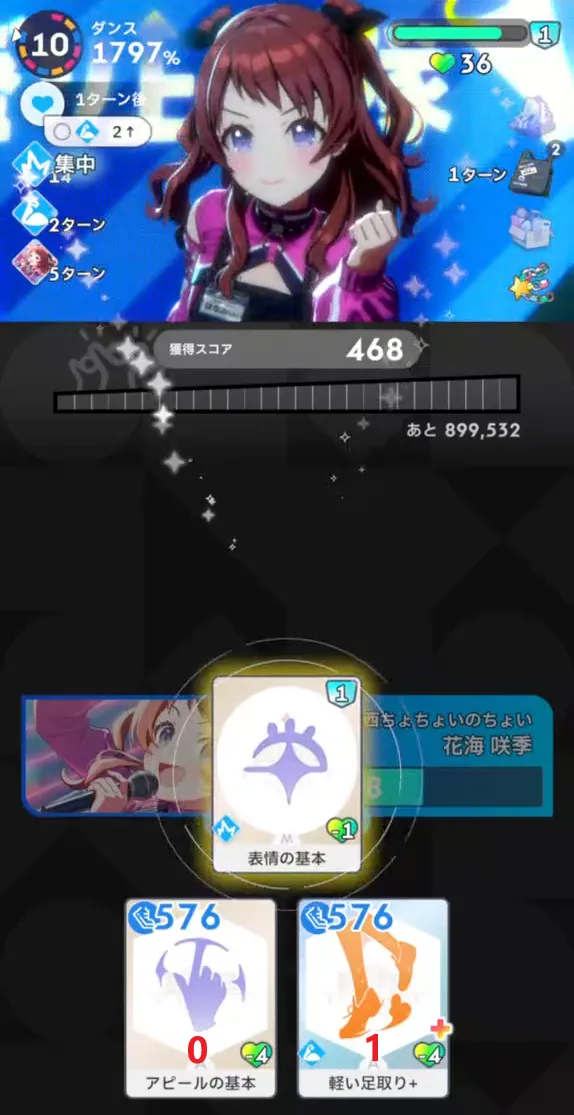
↑ 剩余 10 回合第一张卡使用时
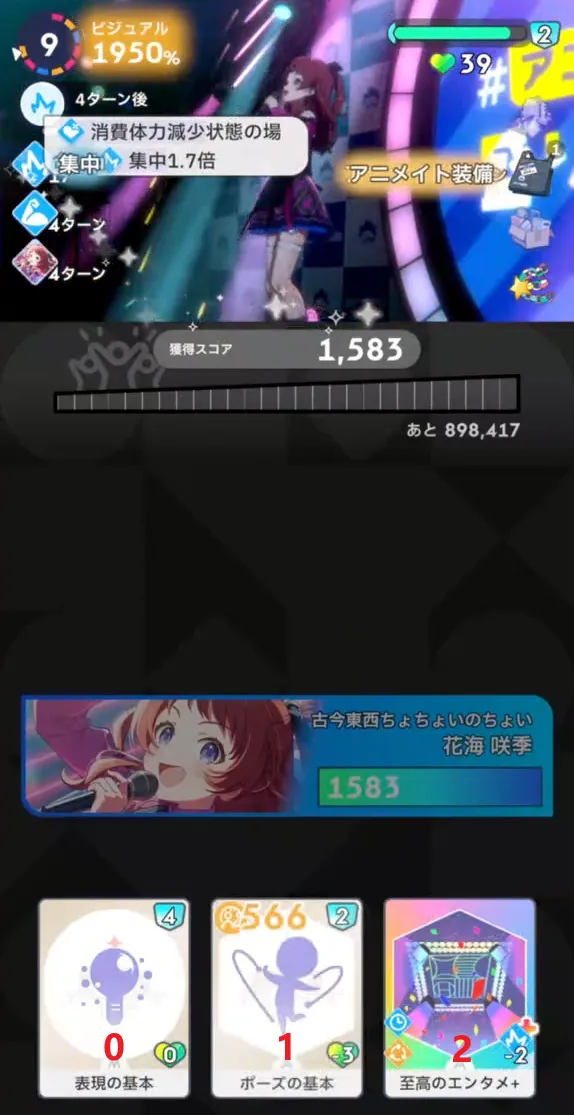
↑ 剩余 9 回合开始时
↑ 剩余 8 回合开始时
为了方便图中为每张手牌标上了序号。calculateTurn 是 2,也就是每 2 回合为一个 step,穷举其中所有组合。这里以上图中剩余回合数为 [10, 9] 时作为例子。
在剩余回合数为 [10, 9] 这个 step 中,由于剩余 10 回合时可以发动两次卡片,所以可选择的排列组合有:
序号
剩余 10 回合第 1 次
剩余 10 回合第 2 次
剩余 9 回合
Eva.
1
0
0
0
1236855
2
0
0
1
1238476
3
0
0
2
2073874
4
0
1
0
1921587
5
0
1
1
1923409
6
0
1
2
3253198
7
1
0
0
1236232
8
1
0
1
1238202
9
1
0
2
2073251
10
1
1
0
1741882
11
1
1
1
1743399
12
1
1
2
2924189
13
2
0
0
1920964
14
2
0
1
1923135
15
2
0
2
3252575
16
2
1
0
1741882
17
2
1
1
1743399
18
2
1
2
2924189
共 18 种。
实际中游戏 AI 会在剩余 8 回合开始时计算以这 18 种方式打出牌后的 evaluation 并选出其中最大。最右的一列已经将计算结果展示出来。0-1-2 时的 evaluation 值最大,所以 AI 最终选择以这个顺序出牌。
我们来手动计算一下这个 evaluation 是如何得出来的。
如果在剩余回合数为 [10, 9] 的 step 中以 0-1-2 的序号出牌,在剩余 8 回合开始时(还记得前面的 evaluation 计算时机 吗?是在效果发动后、抽牌前)玩家所持有的状态中不为 0 的是:
1 2 3 4 5 6 7 8 9 v1 = 2149 // 已获分数 v2 = 2 // 元气 v3 = 39 // 体力 v4 = 15 // 集中 v7 = 3 // min(好调, 剩余回合数) v16 = 1 // 当前可使用卡片数 v18 = 3 // 好调 特殊效果 1: ちょちょいのちょい 特殊效果 2: 至高のエンタメ
同时,这时的 remainingTerm 为:
1 2 remainingTerm = 8 / 2 + 1 = 5
按照前述的计算方式可以算得:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 r1 = 2149 * 96 * 3000 / (18230 + 17970 + 19500) + 0.0000999999975 = 11111.526132 r2 = 2 * 151 = 302 r3 = 39 * 500 = 19500 r4 = 15 * 5435 = 81525 r7 = min(3, 8) * 1108 = 3324 r16 = 1 * 0 = 0 r18 = 3 * 1 = 3
一般参数的和为 115765.526132。
r28 由于目前没有实装,所以为 0。
r29 特殊参数由两个特殊效果来计算。
对于「ちょちょいのちょい」,效果是「ターン終了時、パラメータ+4」。
1 ceiling((4 + 15) * 1.5) * 18.23 = 529
所以,
1 2 3 4 5 6 7 multiplier1 = (1000 / 1000) * 8 // 注意这里即使「ちょちょいのちょい」只剩 3 回合,仍然用当前剩余回合数 8 来计算 = 8 multiplier2 = 529 * 96 * (4000 / 1000) = 203136 r29_1 = int(multiplier1 * multiplier2 + 0.0001) = 1625088
对于「至高のエンタメ」,效果是「アクティブスキルカード使用時、パラメータ+5」。
1 ceiling((5 + 15) * 1.5) * 18.23 = 547
所以,
1 2 3 4 5 6 7 multiplier1 = (900 / 1000) * 8 = 7.2 multiplier2 = 547 * 96 * (4000 / 1000) = 210048 r29_2 = int(multiplier1 * multiplier2 + 0.0001) = 1512345
于是,
1 r29 = r29_1 + r29_2 = 3137433
最终,把一般参数和特殊参数加在一起:
1 2 evaluation = int(115765.526132 + 3137433) = 3253198
以上,在剩余回合数为 [10, 9] 的 step 中以 0-1-2 的序号出牌的 evaluation 值计算完毕。0-0-1 或者 2-1-1 等组合的 evaluation 值,与上表对比一下看看是不是以 0-1-2 的序号出牌后的 evaluation 值最大。
结语 简单来说,自动打牌的逻辑可以总结为 “预先穷举 n 回合后的所有可能性,并选择其中评估值最高的一个进行重现”。相比只计算手牌打出后的即时效果的手动打牌推荐算法来说,将场地、道具、预约等效果都考虑在内,可以说是很全面的一种实现方式。
这种阶段性深度优先遍历模拟算法同时也证实了许多同僚在研究 Contest 时注意到的所谓的 “未来视” 是确实存在的。并且也解释了在 ExamPlayType 为 AutoPlay 时,PlayableValueAdd 的 evaluation 值为什么全部为 0 —— 因为无论是否再动,其造成的结果都已经被计算在了评估值里。